Understanding HDFS: Hadoop Distributed File System
Understanding HDFS
The Hadoop Distributed File System (HDFS) is the storage backbone of the Apache Hadoop ecosystem. It’s designed to store massive datasets reliably across clusters of commodity hardware while providing high-throughput access for data processing.
Why HDFS?
Traditional file systems weren’t built for the scale of modern data. HDFS solves this by:
- Scaling horizontally — add more machines, get more storage
- Handling failures gracefully — hardware failures are expected, not exceptional
- Optimizing for large files — designed for files in GBs and TBs, not small files
- Write-once, read-many — optimized for batch processing, not random writes
Architecture: Master-Slave Model
HDFS uses a master-slave architecture with three main components:
┌─────────────────────────────────────────────────┐
│ HDFS Cluster │
├─────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ │
│ │ NameNode │ ← Master (metadata) │
│ │ (Master) │ │
│ └───────┬───────┘ │
│ │ │
│ ▼ │
│ ┌───────────────┐ ┌───────────────┐ │
│ │ DataNode │ │ DataNode │ ... │
│ │ (Slave 1) │ │ (Slave 2) │ │
│ │ [blocks] │ │ [blocks] │ │
│ └───────────────┘ └───────────────┘ │
│ │
└─────────────────────────────────────────────────┘
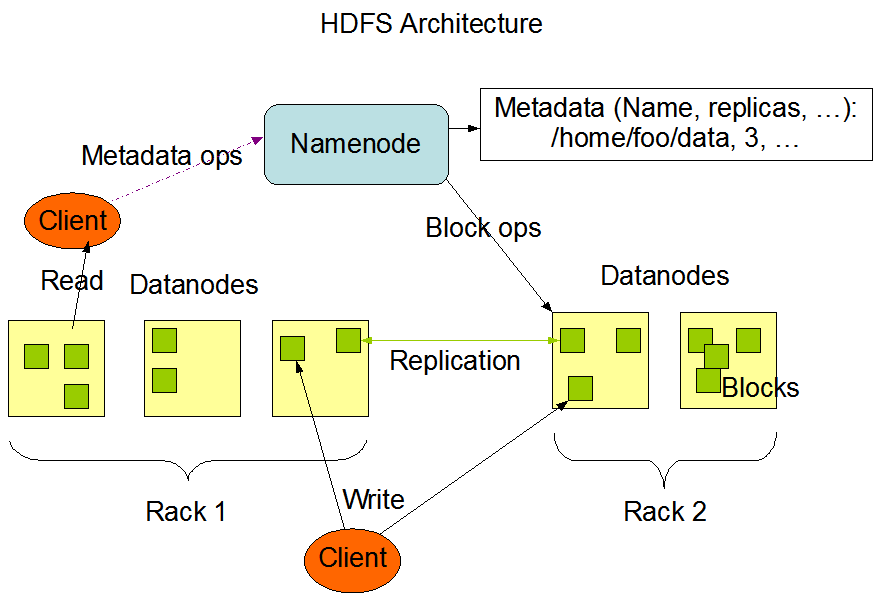
1. NameNode (The Master)
The NameNode is the brain of HDFS. It manages:
- File system namespace — directory tree, file names, permissions
- Block mapping — which DataNodes store which blocks of each file
- Client access — regulating who can read/write files
The NameNode stores metadata in two files:
FSImage— complete snapshot of the namespaceEditLog— journal of recent changes
Important: The NameNode does NOT store actual data, only metadata.
2. DataNodes (The Workers)
DataNodes are the workhorses that store actual data:
- Store data as blocks (default 128 MB each)
- Send heartbeats to NameNode every 3 seconds
- Report block status periodically
- Perform read/write operations as instructed
When a file is written, HDFS:
- Splits it into blocks
- Distributes blocks across DataNodes
- Replicates each block (default: 3 copies)
3. Secondary NameNode
Despite the name, this is NOT a backup NameNode. Its job is:
- Periodically merge
EditLogwithFSImage - Create checkpoints to prevent
EditLogfrom growing too large - Speed up NameNode recovery after failures
How Data Flows
Writing a File
Client NameNode DataNodes
│ │ │
├──── Request write ────►│ │
│◄──── Block locations ──┤ │
│ │ │
├────────── Write data ──────────────────────────►
│ │ (to DN1) │
│ │ │
│ │ DN1 ──► DN2 ──► DN3
│ │ (replication pipeline)
- Client asks NameNode for block locations
- NameNode returns list of DataNodes
- Client writes to first DataNode
- DataNodes replicate in a pipeline
Reading a File
Client NameNode DataNodes
│ │ │
├──── Request read ─────►│ │
│◄──── Block locations ──┤ │
│ │ │
├────────── Read data ───────────────────────────►
│◄─────────────────────────────────────────── data
- Client asks NameNode for block locations
- NameNode returns DataNodes sorted by proximity
- Client reads directly from nearest DataNode
Fault Tolerance
HDFS assumes hardware WILL fail. It handles this through:
Replication
- Each block is replicated (default: 3 copies)
- Replicas placed on different racks for safety
- NameNode re-replicates if a DataNode fails
Heartbeats
- DataNodes send heartbeats every 3 seconds
- No heartbeat for 10 minutes = DataNode marked dead
- Its blocks are re-replicated to other nodes
Checksums
- Data integrity verified using checksums
- Corrupted blocks are automatically recovered from replicas
Key Design Decisions
| Decision | Rationale |
|---|---|
| Large block size (128 MB) | Reduces metadata overhead, optimizes for large files |
| Write-once semantics | Simplifies consistency, better for batch processing |
| Data locality | Move computation to data, not data to computation |
| Rack awareness | Place replicas on different racks for fault tolerance |
When to Use HDFS
Good for:
- Batch processing of large files
- Data lakes and warehouses
- Log aggregation and analytics
- Machine learning training data
Not ideal for:
- Low-latency random access
- Many small files (< 100 MB)
- Frequent file modifications
- Real-time streaming (use Kafka instead)
Summary
HDFS is designed for one thing: storing massive amounts of data reliably and cheaply. It achieves this through:
- Master-slave architecture — NameNode manages metadata, DataNodes store data
- Block storage — files split into large blocks, distributed across cluster
- Replication — every block copied 3x for fault tolerance
- Failure handling — automatic recovery when nodes fail
It’s not the right tool for every job, but for large-scale batch processing of big data, HDFS remains a foundational technology.
Further reading: The original Google File System paper that inspired HDFS.